
Extreme 3D Face Reconstruction - Looking Past Occlusions
CVPR 2018
Anh Tuan Tran Tal Hassner Iacopo Masi Eran Paz Yuval Nirkin Gérard Medioni
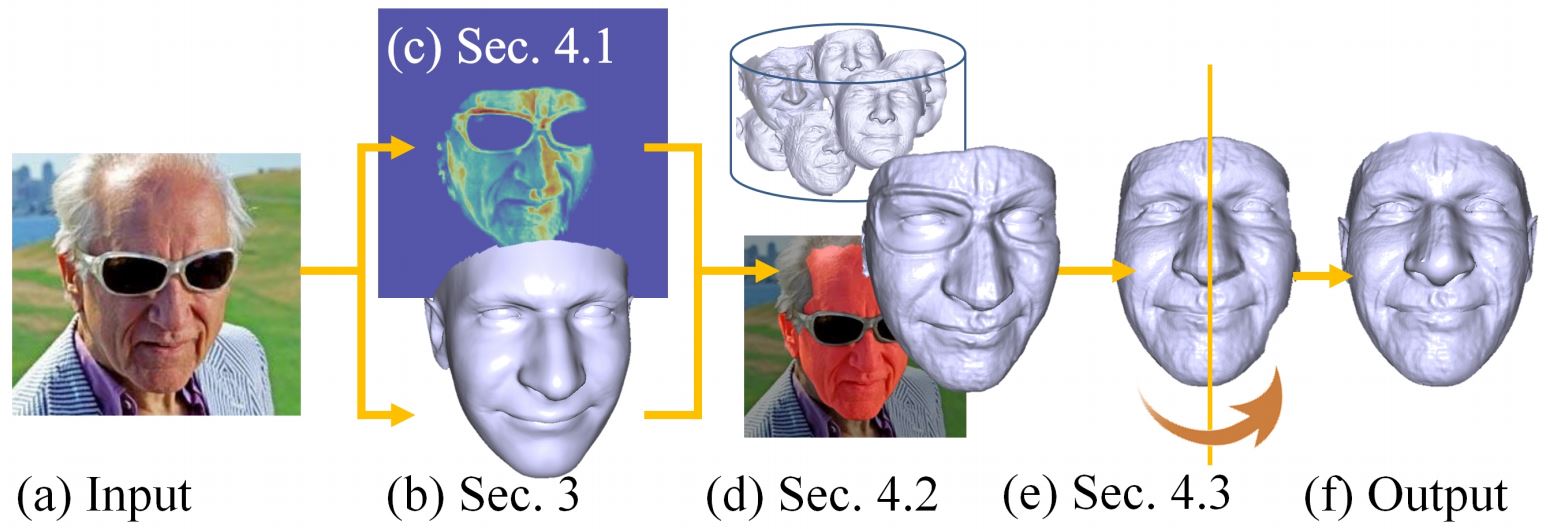
Existing single view, 3D face reconstruction methods can produce beautifully detailed 3D results, but typically only for near frontal, unobstructed viewpoints. We describe a system designed to provide detailed 3D reconstructions of faces viewed under extreme conditions, out of plane rotations, and occlusions. Motivated by the concept of bump mapping, we propose a layered approach which decouples estimation of a global shape from its mid-level details (e.g., wrinkles). We estimate a coarse 3D face shape which acts as a foundation and then separately layer this foundation with details represented by a bump map. We show how a deep convolutional encoder-decoder can be used to estimate such bump maps. We further show how this approach naturally extends to generate plausible details for occluded facial regions. We test our approach and its components extensively, quantitatively demonstrating the invariance of our estimated facial details. We further provide numerous qualitative examples showing that our method produces detailed 3D face shapes in viewing conditions where existing state of the art often break down.
Overview
Downloads
 |
|
| Paper | Code |
Citation
@inproceedings{tran2017extreme,
title={Extreme {3D} Face Reconstruction: Seeing Through Occlusions},
author={Tran, Anh Tuan and Hassner, Tal and Masi, Iacopo and Paz, Eran and Nirkin, Yuval and Medioni, G\'{e}rard},
booktitle={IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year=2018
}